This demo introduces SchroWave, which can generate realistic singing voice with given middle voice features, e.g. mel-spectrogram as input.
In recent years, methods based on discrete diffusion models have achieved state-of-the-art performances in voice generation. In theory, the voice data can be transformed into the exact Gaussian prior distributions only when the diffusion time tends to infinity. But in real applications, the Gaussian prior distribution can only be achieved approximately in a limited time duration run by these diffusion-based methods, thus resulting in sub-optimal sound quality. In this paper, we present the SchroWave to realize the continuous transformation from exact Dirac’s deltas to the target voice data distribution in finite time duration, conditioned on middle voice representation with different size. At the same time, in order to overcome the difficulty in calculating the score on the low-dimensional manifold of voice data during the generation process, we propose to use a two-stage diffusion and generation method, while each stage implemented by solving a conditional Schrodinger bridge problem. Our experiments on the public data set LJSpeech show that the effect is significant in both objective and subjective evaluation, and achieve the new state-of-the-art MOS of 4.53.
Frameworks, pipelines, modules, and algorithms in SchroWave
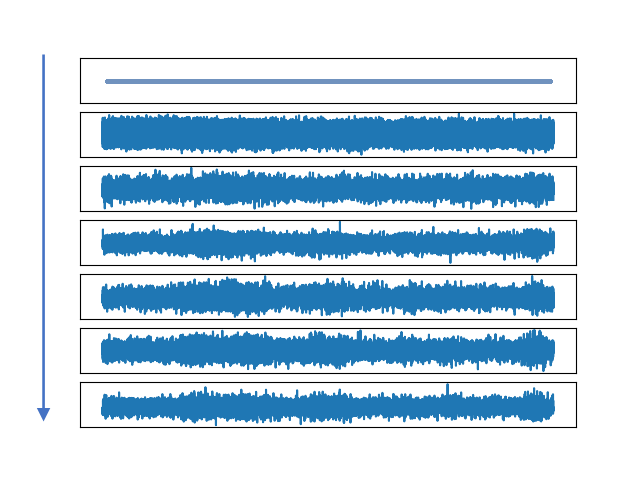
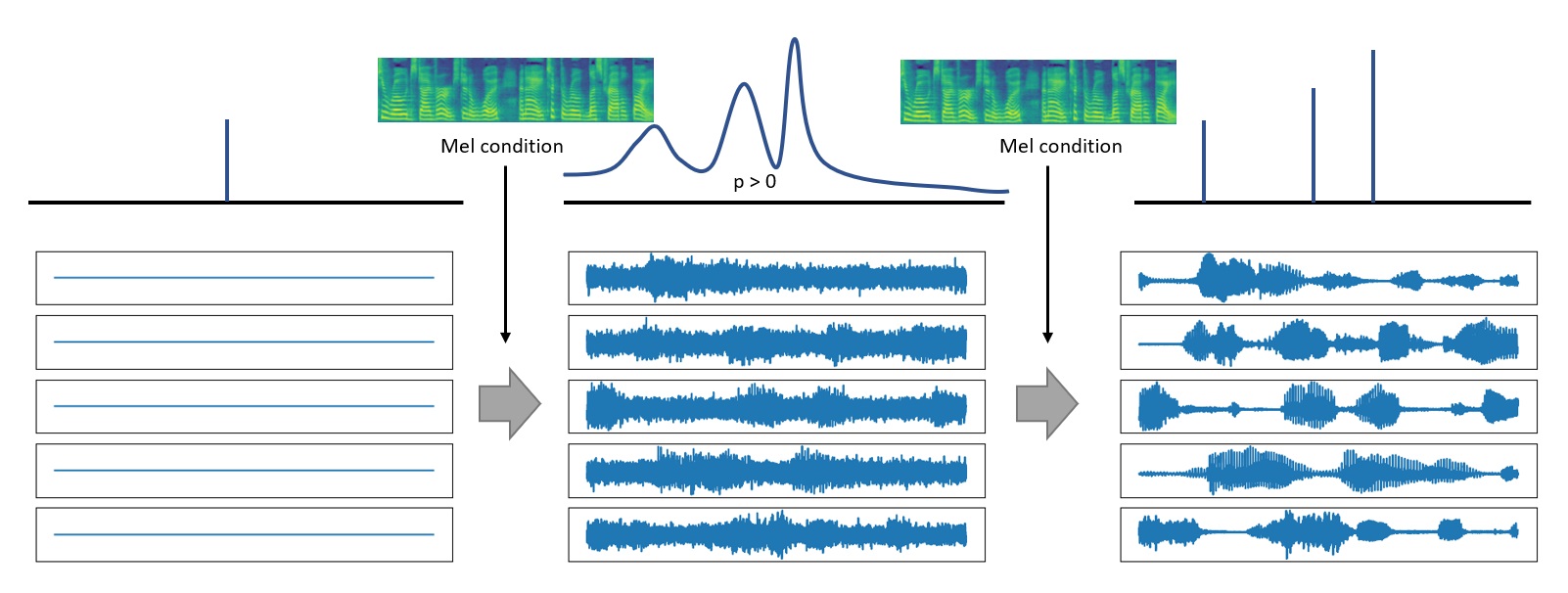
Example of two-stage wave generation in SchroWave. In the first stage, the data from the Dirac's distribution is transformed into the noisy target wave distributed over the whole ambient Euclidean space; in the second stage, the noisy wave is mapped into the distribution of clean target voice.
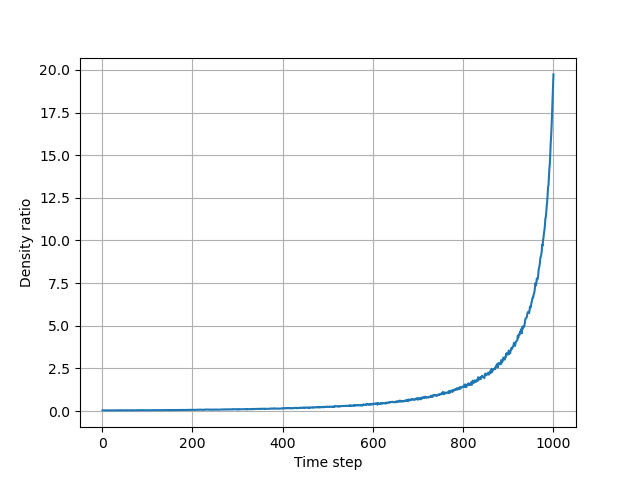
The density ratio evolves with the diffusion step.
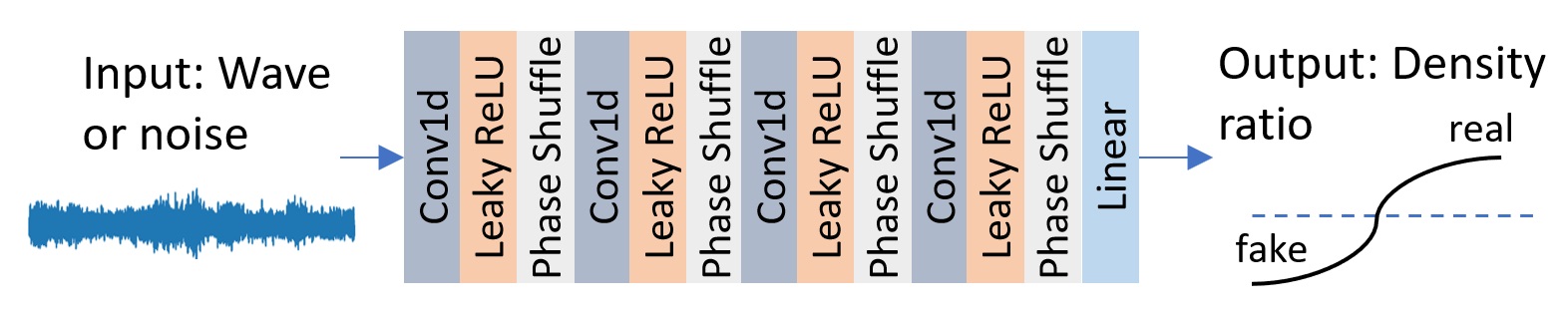
The density ratio prediction network in SchroWave.
The score prediction network in SchroWave.

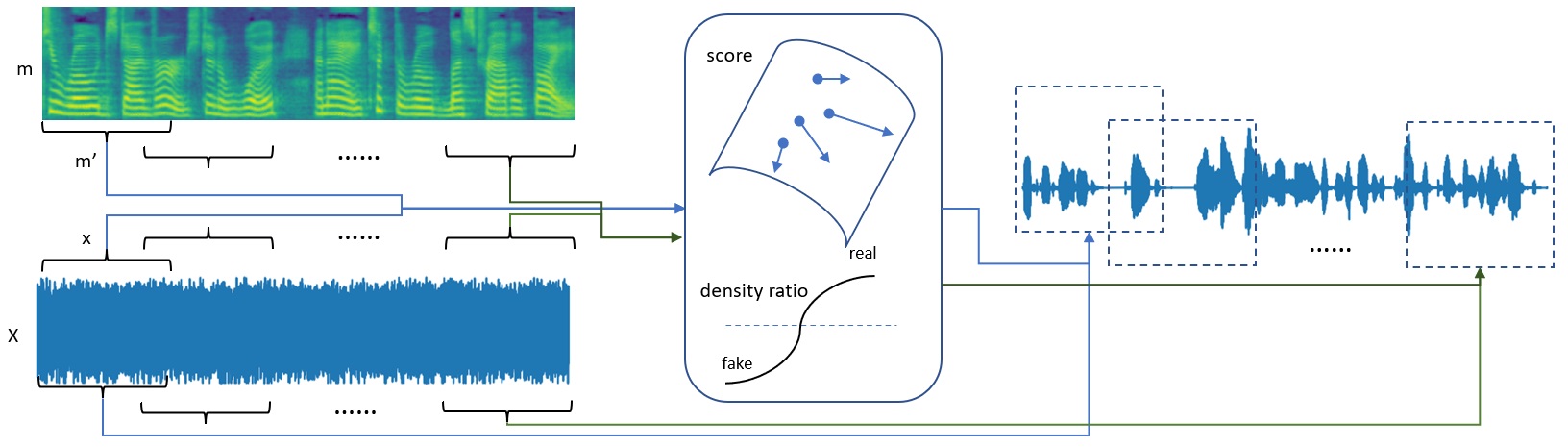
Parallel voice segmentation and diffusion.
Modules in score prediction network. (a) Time step embedding; (b) the residual block; (c) mel-spectrogram up-sampling.

Two stages of wave generation in Schr\"oWave. (a)The generation steps of the noisy wave from Dirac distribution in the first stage. (b)The generation steps of the clean wave from the noisy wave in the second stage.